Originally published on the InterWorks blog.
In Part One of this series, I laid out five reasons data science projects fail. Management frameworks that don’t fit the work. Data problems. Outdated tools. Organizational resistance. And data scientists who lose the thread to business value.
Now for the other side: what does success actually look like?
Why Data Science?
People often ask why organizations need data science when visualization already exists. The answer is a matter of dimensions.
Humans are limited in their ability to see — and in effect, our dashboards are limited as well. We cannot perceive anything greater than three dimensions. Machine learning and AI operate beyond that boundary. They remove bias, automate complex tasks, and discover relationships in high-dimensional data that no human analyst could ever find manually. What would take decades of Excel scrolling can be accomplished in hours.
Anticipating the future or discovering unique trends in your customers’ behavior are now realistic outcomes — not just aspirations. That’s why data science matters, beyond what visualization alone can offer.
Laboratories Are the Answer
The most important reframe I can offer: stop treating data science like software development. Start treating it like laboratory research.
Software development has known inputs and defined outputs. Data science has hypotheses and experiments. The mindset that works for one actively breaks the other. When organizations impose rigid project management structures on data science work — fixed scopes, guaranteed outcomes, standard sprint cycles — they set themselves up for exactly the kinds of failures I described in Part One.
A laboratory mindset accommodates uncertainty. It makes room for iteration. It treats dead ends as information rather than failures. And critically, it creates space for the kind of tinkering that produces unexpected insights: tinkering allows members across multiple projects to poke and prod one another’s ideas, and that cross-pollination often generates the most valuable work.
The Laboratory Team
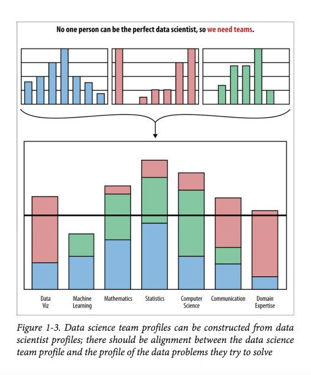
The unicorn data scientist — equally brilliant at statistics, engineering, communication, and domain expertise — largely does not exist. Stop looking for one.
What does exist is a team of three or four specialists who collectively cover those domains. Hierarchies of expertise naturally emerge when people with different skill sets collaborate. The synthesis produced by that kind of diverse team is consistently stronger than what any individual could produce alone.
This point is made well in Doing Data Science, and it bears repeating: build a team, not a superhero.
The Laboratory Rules
The environment needs to encourage experimentation. That means minimizing rules — down to the ones that actually matter.
The rules that matter: protecting sensitive data, maintaining ethical and legal compliance, ensuring that outputs can be trusted. These safeguards are real and important.
Beyond those, most organizational rules imposed on data science work are counterproductive. Bureaucratic overhead is the enemy of discovery. Data scientists need room to explore before committing to solutions — and organizations that don’t provide that room shouldn’t be surprised when their data science investments stall.
The Laboratory Environment
Five technical requirements for a functional data science environment:
- Access to all available data sources — restricted data is the single fastest way to constrain what’s possible
- Support for multiple programming languages — teams have different tools; enforcing a single language stack limits hiring and output quality
- Tools that minimize data cleaning time — every hour spent wrestling with data pipelines is an hour not spent on actual science
- Scalable cloud infrastructure — problems worth solving often require more compute than a laptop
- Collaboration infrastructure — version control, shared resources, and communication systems that make joint work natural rather than friction-filled
Fitting the Laboratory into Existing Systems
One concern I hear often: if data science operates like a laboratory, how does it connect to the rest of the organization?
Think of the data science team as a helicopter that can deploy outputs anywhere in the existing infrastructure. Tableau reports, API endpoints, embedded applications, model scores pushed to CRM systems — the laboratory produces these things. It doesn’t replace the systems that consume them. It integrates with them.

Dataiku
One tool worth calling out specifically: Dataiku. It’s designed around the actual data science process in a way that most platforms are not.
For business users, it provides drag-and-drop interfaces that make participation in data workflows accessible without requiring programming knowledge. For data scientists, it provides flexible coding environments that don’t constrain how you work. For IT teams, it provides API deployment capabilities and governance controls.
What I appreciate most is that the tool was clearly designed by people who understood how data science actually operates — not how someone imagined it might operate from the outside.
Final Thoughts
Success in data science requires three things working together: a focus on business value, genuine team collaboration, and an environment that supports exploration.
When organizations reduce the bureaucratic friction their data scientists fight every day, those scientists can direct their energy toward solutions and toward communicating those solutions clearly. That’s where real organizational value comes from.
The laboratory model isn’t complicated. It just requires the organizational will to treat data science like the research it actually is.
This is Part Two of a two-part series. Part One covers the most common reasons data science projects fail.